

Pythonその3 青空文庫にある戯曲を読みやすい縦書き台本形式に成型する
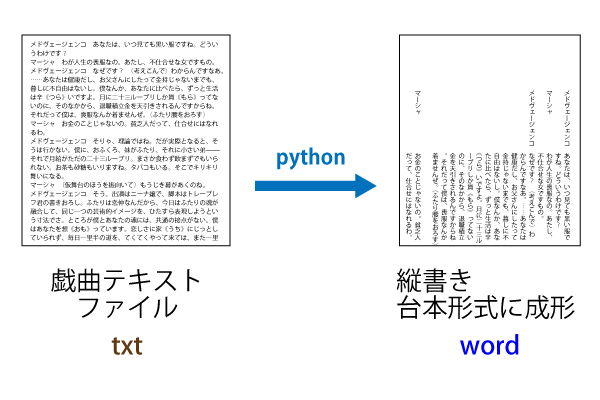
青空文庫には戯曲がたくさん置いてあって、しかも無料で読むことができるのでとても便利です。
ただ、シンプルなテキストファイルになっているので、いわゆる「読みやすい台本の形」にはなっていません。
友人のゆかりーぬさんも「台本形式への成形はなかなか大変なんです」と言っていたので、青空文庫にあるようなシンプルな戯曲テキストファイルを、ある程度読みやすい縦書きワードファイルに成型するpythonプログラムを作ってみました。
#! python3
# 青空文庫にある戯曲を読みやすい縦書き台本形式に成型する
from docx import Document
from docx.shared import Cm
from docx.shared import Pt
import openpyxl
#wordファイルオブジェクトを生成
document = Document('template.docx')
#エクセルファイルを読み込み
wb = openpyxl.load_workbook('setting.xlsx')
sheet1 = wb['Sheet1']
#設定値
c = sheet1['B2'].value #役名部分の文字数
h = sheet1['B3'].value #せりふ部分の文字数
indent = 4 - (h - 19)*4/10 #インデント(役名の上の余白)
kaishigyo = -1 + sheet1['B4'].value #せりふが始まる行数
gikyoku_title = sheet1['B5'].value + '.txt'
#戯曲テキストファイルを読み込み
gikyoku_file = open(gikyoku_title)
lines = gikyoku_file.readlines()
#word側に記述(せりふより前のブロック)
for j in range(1,kaishigyo):
line = lines[j].replace('\n','')
paragraph = document.add_paragraph(line)
#word側に記述(一行あける)
paragraph = document.add_paragraph()
#word側に記述(せりふブロック)
for i in range(kaishigyo, len(lines)):
line = lines[i].split(' ') #ある行の役名とせりふを(スペース)で分割して役名を取得
serif_len = len(lines[i]) - len(line[0]) #せりふの文字数を取得
cast = line[0].ljust(c, ' ') #役名部分が上で設定した文字数になるようにスペースを追加
c_moji = len(line[0])+1 #役名の文字数+1
serif = lines[i][c_moji:c_moji+h] #せりふ部分の文字列の最初の一行を取得
x = 1 #カウンタ
#せりふの2行目以降を取得
while serif_len > h:
serif = serif + '\n' + ' '*c + lines[i][c_moji+h*x:c_moji+(h*(x+1))]
x = x + 1
serif_len = serif_len -h
#役名とせりふをWord側に記述
text = cast + serif
paragraph = document.add_paragraph(text)
paragraph.paragraph_format.left_indent = Cm(indent)
#wordを書き出して保存
seikeizumi = sheet1['B5'].value + '-seikei.docx'
document.save(seikeizumi)
print('書き出し完了')
使い方
1)まず、Pythonをインストールします。
「python インストール」などと検索して、なんとか自分のパソコンにインストールしてください。
実は僕の場合、インストールで結構つまずきました。いろいろやり方があるらしいんですが、公式(https://www.python.org/)からダウンロードしてインストールするのが一番うまくいきました。僕の場合は。
2)次にモジュールをインストールする
今回は、python-docxと、openpyxlを使います。
macの場合→ターミナルというのを立ち上げて、
$ sudo pip3 install python-docx $ sudo pip3 install openpyxl
Windowsの場合→コマンドプロンプトというのを立ち上げて、
$ pip install python-docx $ pip install openpyxl
とかやって、インストールしてください。
いろんなサイトで各モジュールをインストールするやり方は説明されているので調べてみてください。
3)pythonファイルをダウンロード
こちらからダウンロードして、zipファイルを解凍してください。
daihon-seikei
この中に、
daihon_seikei.py
setting.xlsx
template.docx
青空文庫からダウンロードしてきた
kamome.txt
の4つが入っています。
4)エクセルのリストを変更する
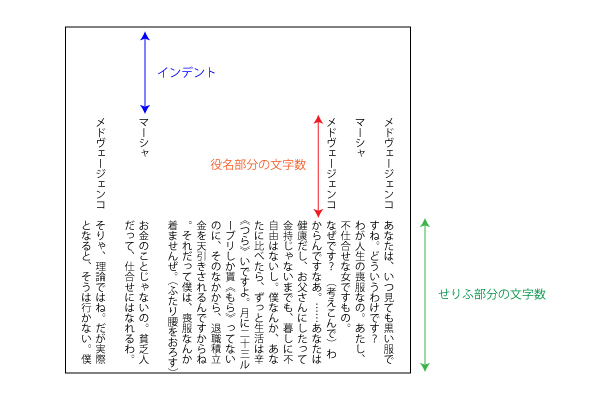
setting.xlsxというファイルをエクセルで開いて、必要に応じて修正していきます。
チェーホフのかもめの場合、役名で一番長いのは「メドヴェージェンコ」→つまり9文字だったので、ひとつ空白を入れるために「役名部分の文字数」は10文字にしています。
「せりふ部分の文字数」は19文字にしてみました。役名が短い場合は、この2つの設定を調整すると読みやすいと思います。
「インデント(役名の上の余白)」は、せりふの文字数が増えると減り、逆にせりふの文字数を減らすとインデントは増えるようにしてあります。とはいえ、カンパニーによって(演出家によって?)インデントは好きな値が異なると思うので、出来上がったワードファイルを操作して調整するとよいと思います。
せりふが始まる前は、登場人物紹介などでインデントを入れる必要がないので、せりふの始まる行(つまりインデントを始めたい行)を指定してください。元の戯曲ファイルをメモ帳で開いて、せりふが始まる行を選択すると(〇〇行)と表示されるので、それを指定すると便利です。
5)daihon_seikei.py をIDLEで開いてF5で実行!
すると、
同じフォルダの中にワードファイルが生成されます。
実際に生成したファイルはこちら
kamome-seikei
僕が試してみたところ「かもめ」「ワーニャ伯父さん」「桜の園」はある程度うまくいきました。
仕掛けとしては、役名とせりふの間の【スペース】を探して、役名ブロックとせりふブロックを分割して成型する、ということをやっています。なので、役名とせりふの間に【スペース】がない形式の戯曲には使えません。たぶんヘンなことになると思います。
daihon_seikei.py の40行目にその記述があるので、「・」で区切ってある戯曲や、せりふをカッコで分けてあるものなどは、pythonのコードをうまいことカスタマイズしてみてください。
ひとつ残念なところは、句読点も普通の文字と認識しちゃうので、行頭に「、」や「。」が出ちゃうんです・・・。これを回避するうまい方法が僕のレベルではまだ思いつかなかったので、もしうまい方法があれば、どなたかぜひ教えてください!
※Macで試すと、UnicodeDecodeErrorというのが出て止まってしまいました・・・。調べてみたところ、これはテキストファイルがShift-JISで保存されている場合に発生するようです。そういう時は元の戯曲テキストをテキストエディットで開いて、テキストエンコーディングをUTF-8にして保存し直すとうまくいきました。Windowsではなんにも言われないのにね。
(文:森脇孝/エントレ編集部)